Багато популярних платформ та бібліотек ML вже пропонують можливість використовувати прискорювачі GPU для прискорення процесу навчання з підтримкою інтерфейсів, таких як TensorFlow, CNTK, Theano, Keras, Caffe, Torch, DL4J, MXNet, Chainer та багато іншого [DLwiki] [Felice 2017 ] [Kalogeiton 2017]. Деякі з них також дозволяють використовувати оптимізовані бібліотеки, такі як CUDA (cuDNN) та OpenCL, щоб ще більше підвищити продуктивність. Головною особливістю багатоядерних прискорювачів є масово паралельна архітектура, що дозволяє їм прискорювати обчислення, що передбачають операції на основі матриці. Інтерес до GPGPU можна знайти у багатьох інших широкомасштабних модельних пакетах з динамічним прогресом.
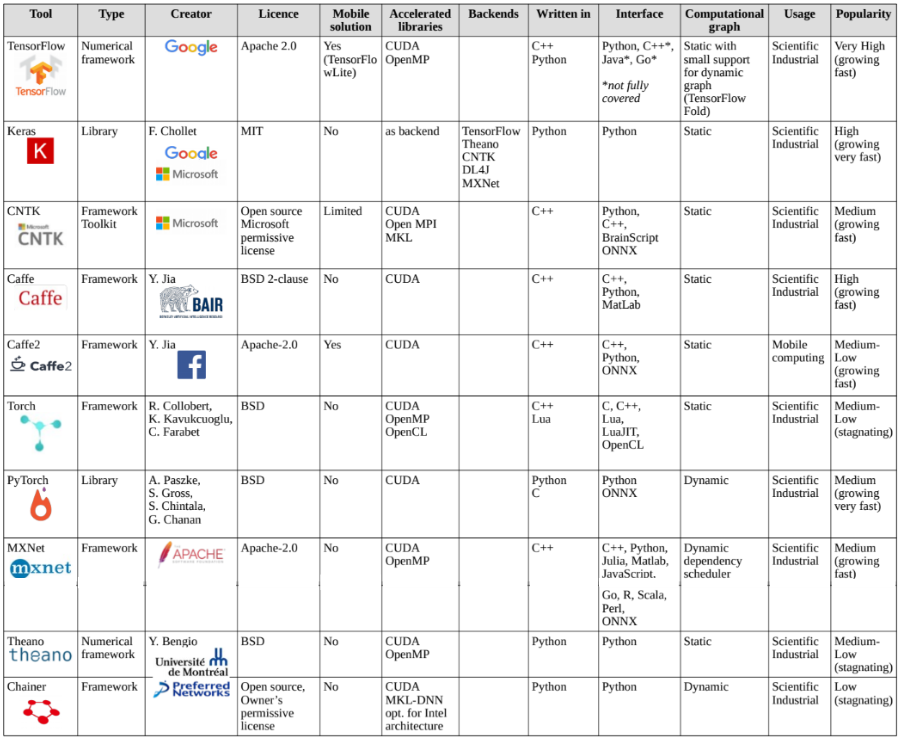
Показники популярності і трендів можуть бути змінені відповідно до високою динамікою розвитку платформи та інструментів DL. Оцінка цих значень була заснована на репозиторії спостереженні зірок в Github [Jolav 2018].