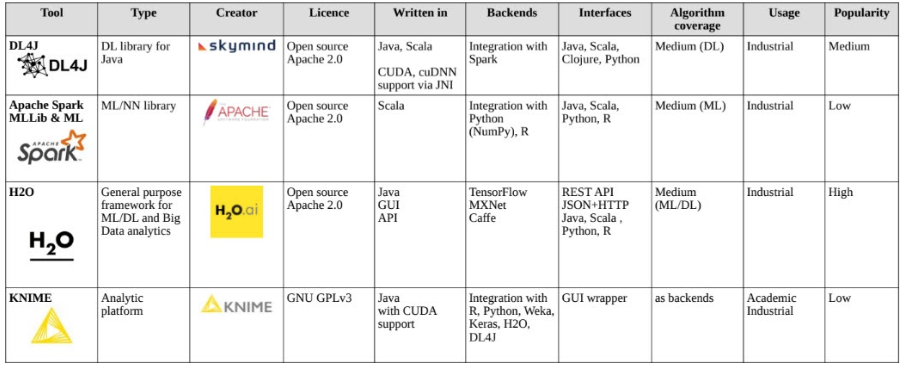
Нещодавно з’явилися нові розподілені платформи для вирішення завдань масштабованості алгоритмів для аналітики Bigdata з використанням моделі програмування MapReduce. Це Apache Hadoop і Apache Spark, дві найбільш популярні реалізації. Основними перевагами цих розподілених систем є їх еластичність, надійність і прозора масштабованість в зручній для користувача формі. Вони призначені для надання користувачам простого і автоматичного відмовостійкого розподілу робочого навантаження без незручностей, пов’язаних з певними деталями базової апаратної архітектури кластера. Ці популярні розподілені обчислювальні середовища і графічні процесори не є взаємовиключними технологіями, хоча вони націлені на різні цілі масштабування [Cano 2017]. Ці технології можуть доповнювати один одного і призначатися для додаткових обчислювальних сфер, таких як ML і DL [Skymind 2017], однак тут все ще багато обмежень і проблем.